

Everything you need to know about getting started with Assets for Jira Service Management Data Center.

Getting started with Assets for Jira Service Management Data Center
This guide is for anyone getting started on setting up Assets for Jira Service Management Data Center. With Assets, teams can track their assets, configuration items, and resources to gain visibility into critical relationships between applications, services, underlying infrastructure, and other key assets. Assets are built on Jira, giving teams a simple and quick way to tie assets and configuration items to service requests, incidents, problems, changes, and other issues to gain valuable context.
Step 2 - Understand how Assets is structured
This section will give an overview of how the Assets database is structured.
Objects
Objects are your actual assets/configuration items. These can be linked to your Jira issues so whenever an issue comes in, the issue immediately has more context.
They can also be linked with each other using object references to show how objects depend on each other.
Object Schemas
An object schema is the actual configuration management database (CMDB) that contains your object types (more on those below) and objects. You can create multiple object schemas in Assets which is useful for a number of reasons:
- Breaking data into smaller chunks helps with auditing the data and keeping it accurate.
- If you have sensitive data, e.g. employee information, it may be simpler to keep all that data together in one object schema with restricted access permissions.
When deciding how to put data into Assets, consider the uses of the data and who will update it so the data can be grouped into logical object schemas.
Assets (and by extension Jira Service Management) does not care about which information is contained in which object schema. It just sees one big pool of data. This means you can easily use multiple object schemas for one use case and create links between objects in different object schemas.
Object Types
Object types go within a schema and define the objects that the schema contains. You can define these yourself or you can use an object schema template that will come pre-populated with certain object types that you can customize. Object types act as containers for your actual objects. Object types can be whatever you want them to be as Assets is very open and flexible but common object types include:
- Business services
- Hosts
- Laptops
- Software
But they don’t have to be IT assets. For example many people add other useful information such as:
- Vendors
- Locations
- Employees
- Business Priority
You can organize object types in the hierarchy tree in a way that makes sense. This tree is mainly for navigation and readability and you can have empty object types to aid this, but it can be setup to offer inheritance of attributes to make creating object types easier.
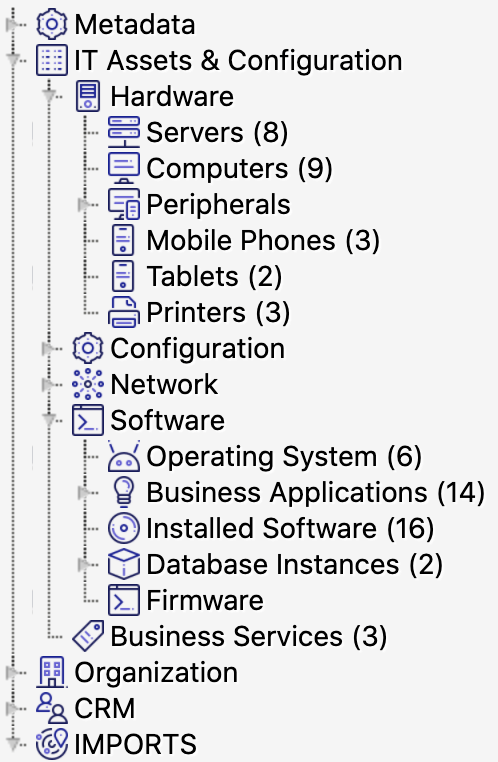
Object Type Attributes
Object attributes are what define an object type. Each object type will have its own set of attributes. For example, the object type “laptops” might have the attributes: model, serial number, user, warranty expiry date etc.
Entering actual values for the attribute will define an object. This can be done manually or automatically (see Step 4).
All object types will have four mandatory attributes:
- Name
- Key
- Created Date
- Last Updated Date
The last three are set automatically. Every other attribute can be defined by the admin. And because there’s a unique key attribute, the name of each object does not need to be unique.
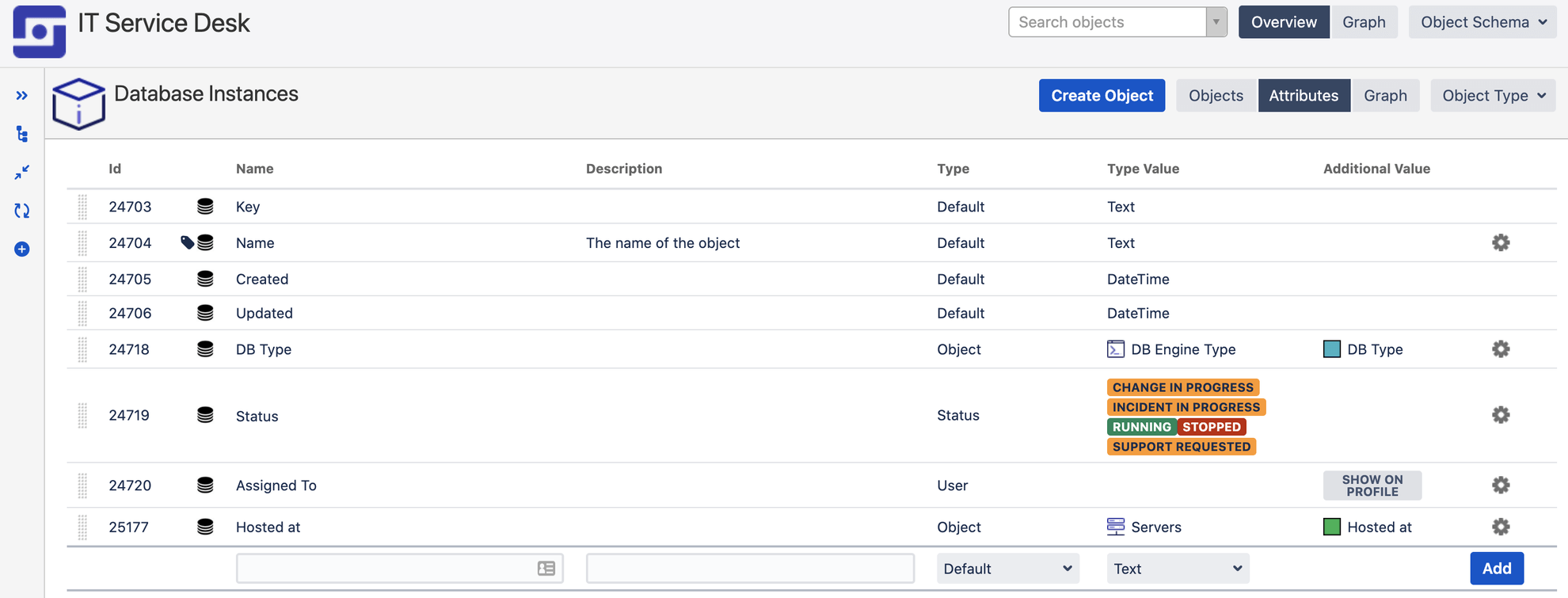
Attributes can comprise of many different data types including text, dates, numerics, URLs (great for linking to other stores of information or service contracts), Jira users (excellent for setting ownership of objects), statuses (in stock, assigned, retired, etc.), and other objects (more on this in the next section).
Object References
An object attribute to call out specifically is the attribute type of “object.” This creates a reference to other objects and it is how you start building a map of dependencies between your objects.
For example, if location is its own object type, then each location object can be one of your business' office locations. This allows you to quickly set the location for every laptop by selecting “Stockholm” for example.
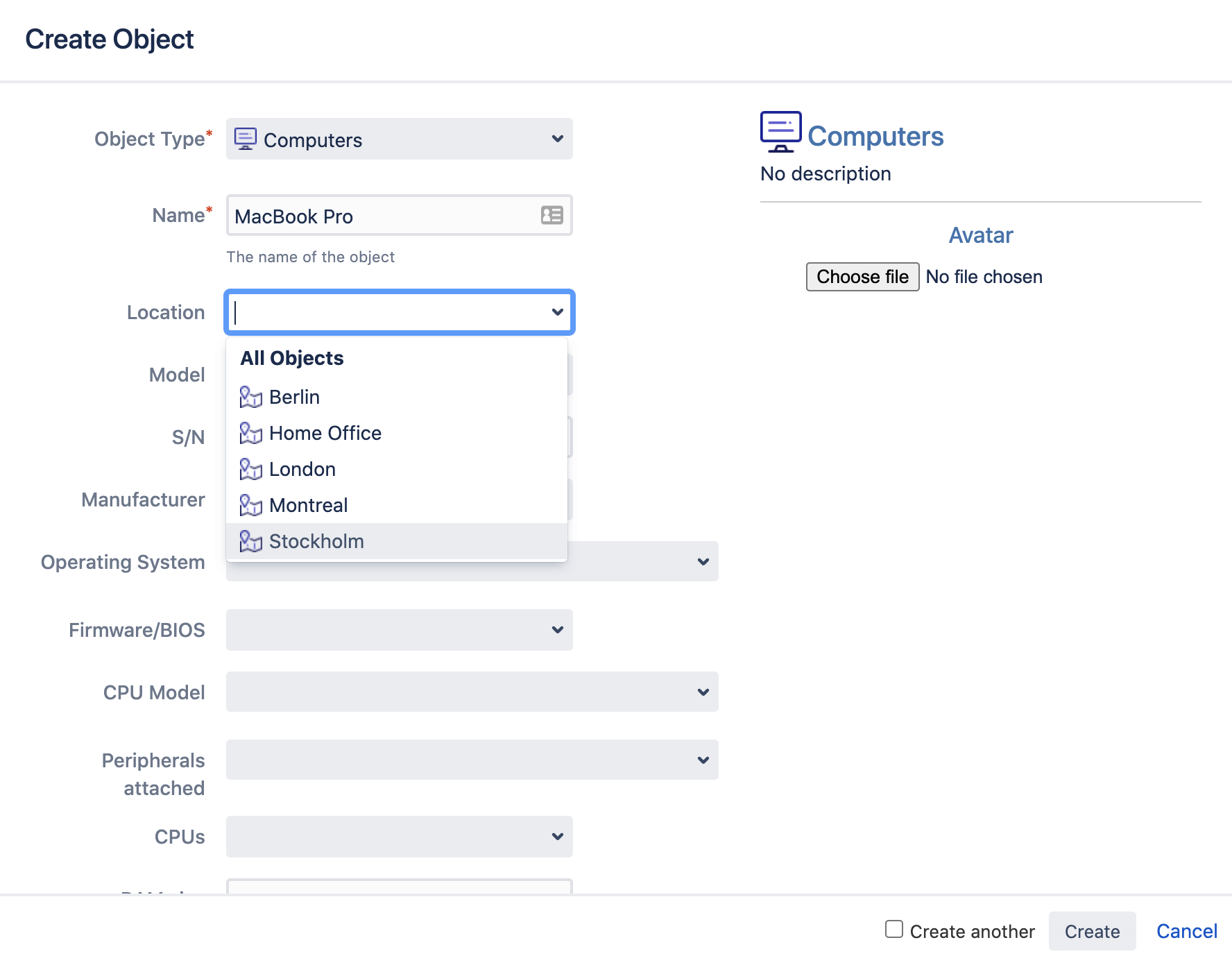
Object references don’t have to bet set manually. They can be added automatically from network scanners, importers, automation rules, etc. See step 4 for more details on these.
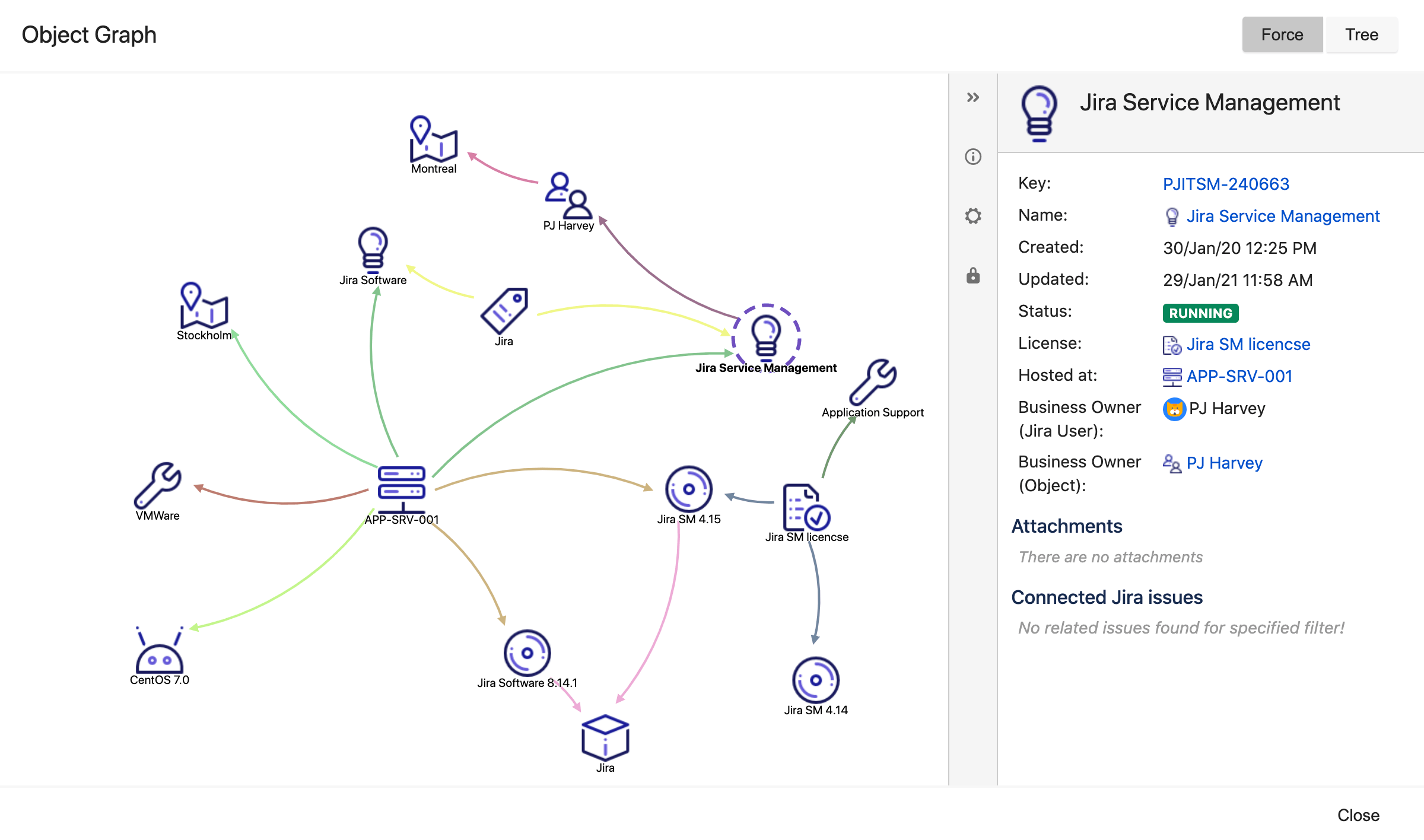
References between objects have two main benefits:
Major benefit - You can map dependencies between your objects. For example, you can map your business services to the different hosts, operating systems, and files they depend on. This map can be incredibly useful for understanding the downstream effects of changes (if I change this OS, what might be impacted?), as well as finding the causes of incidents and problems. And because each object can be linked to a Jira issue, over time you build up a comprehensive history of your infrastructure or other business assets which further helps with solving issues and problems.
Minor benefit - It is easier to manage. If an office moves from say Montreal to Toronto, you only need to update the object Montreal rather than go through each laptop changing Montreal to Toronto.
There are two types of object references:
- Outbound references are references from the current object to other objects.
- Inbound references are other objects that refer to the current object.
References between objects can be viewed using the graphical viewer. You can decide what reference types you have (e.g. installed on, owned by, vendor) and you can color code these in the object schema settings.
Assets Permissions
Assets has three types of permissions
- Global Permissions - In global settings, you can specify who should have administrative permissions in Assets. People assigned to the “Assets Administrator” role can perform all actions within Assets.
- Object Schema Permissions - In object schema settings, you can define who has administrative permissions for a particular object schema, who can update object schema data, and who can just view the data.
- Object Type Permissions - Sometimes you might want Jira Service Management customers to only see certain information in an object schema but you don’t want to give them access to view all the data within the entire object schema. You can use object type permissions here.
Step 3 - Choose what data to include
Every instance of Assets will be unique as every company requires different information to be tracked. Assets can store any piece of information that is useful for you and your business to know and understand.
What specific assets or configuration items you should include will depend on what you are trying to do. An Assets instance for inventory management is going to look very different from one used to map business services and their dependencies for making changes and solving incidents faster.
Here is our top advice for deciding what data should be included:
Define your problem
Most tools are implemented to solve a problem, and Assets is no exception. It could be that your incident resolution time is not as fast as you’d like, or perhaps changes to a specific service often cause unexpected outcomes because you can’t easily see service dependencies.
Find your problem and use that to define everything else, from who you involve to what assets and information you include in your database. Look at the problem and understand what extra information staff need to help them overcome it. This information will define your object types.
Adding too much information at once can make it tough to check accuracy so try to focus on one problem at a time. Once your first problem is solved, Assets can grow to solve other problems.
Start with services
For configuration management uses, we recommend starting with the services related to the problem you're trying to solve. Services are well defined, and it’s relatively simple to start adding the various assets they depend on to run, and in turn, the assets that those assets depend on, and so on. Eventually, you’ll build up a complete picture of each relevant service and its dependencies.
You do need to decide how deep to go. Realistically think how much detail you need to understand your services. Mapping the specific racks and cables will be too much detail for some, but for others, that may be required.
You also don’t need to do all of your services at once. You could start with just your business critical services or those that are having the most downtime.
Starting with services gives a defined set of assets/configuration items to start with. You can then add other assets as needed, when new problems arise. It’s best to build your CMDB bit by bit as it’s easier to confirm the accuracy of small chunks of data than your entire infrastructure and assets all at once.
Use object schema templates
Assets comes with object schema templates for IT asset and configuration management, human resources, and customer relationships management.
These templates can be modified to suit your needs, but they’re a good starting point to the types of objects people often store in Assets. Go down the list of object types and remove any you won’t use.
Tips & Tricks
Think about what you can live without
Think carefully about what you are trying to achieve and what information is needed to do so. Each object and its attributes should be useful.
You should sit down with your team and any stakeholders and ensure each attribute is being consumed by someone or something. If nobody has a specific use for it, then it gets binned. It can always be added later!
Do you really need to know the exact location of your servers? Or the manufacturer of your operating systems? Maybe you do, and that's perfectly valid. But if you’re not going to make a decision or query based on that data, then into the scrap pile it should go!
Adding too much data has its challenges:
- The more objects and attributes you have, the more work is needed to keep them accurate.
- Lots of unused data will obscure the valuable data and could even degrade performance in extreme cases.
- It is easier to add data later than remove it. So if you discover you’re missing something, add it in later rather than starting off with loads of data ‘just in case.' Nobody likes deleting data.
Consider future maintainability
Consider how you will maintain the data when it’s in Assets. How often does an object’s attribute(s) change and how easy will it be to keep it up to date in Assets?
If a particular detail of an object changes often but it's rarely used, it probably makes more sense to keep it out of Assets and just look it up on the few occasions it’s actually needed. If something is used every now and then but is very static, then it may be worth including for ease of access.
Let’s take laptop software as an example. You could, if you wanted, update Assets to include every piece of software installed on the laptop using a scanning agent, software request issues, and automation rules. If you have an open installation policy then this is going to change relatively quickly and scanning patterns may not pick up new pieces of software so the accuracy might be a bit off. Instead, it’s probably better to look at a key set of software that you’re particularly interested in understanding the usage of.
If you have strict installation policies and software only gets installed at laptop setup and through service desk requests, then it may make sense to store it all in Assets as the rate of change is slower and it’s easier to track.
Think beyond physical items
As Assets let you define the objects you need, you aren’t limited to traditional or even physical assets. Business services, for example, are not physical assets but they’re often critical for people to understand in detail. You can link all of a service’s physical and non-physical dependencies to it so just by looking at a business service object, you can get a full understanding of how it’s running.
You can go as abstract as you’d like. Common examples of Assets users create include objects of business importance, environment types, departments/teams, locations, etc.
Another real-world example is categorizing business services. Let us say all your business services are added to Assets under the object type “Business Services.” You may want to categorize those business services into “Finance,” “Logistics,” “Sales,” “Infrastructure,” etc. You could do this with an attribute in the Business Service object type or you can make these categories their own object type called “Service Category.”
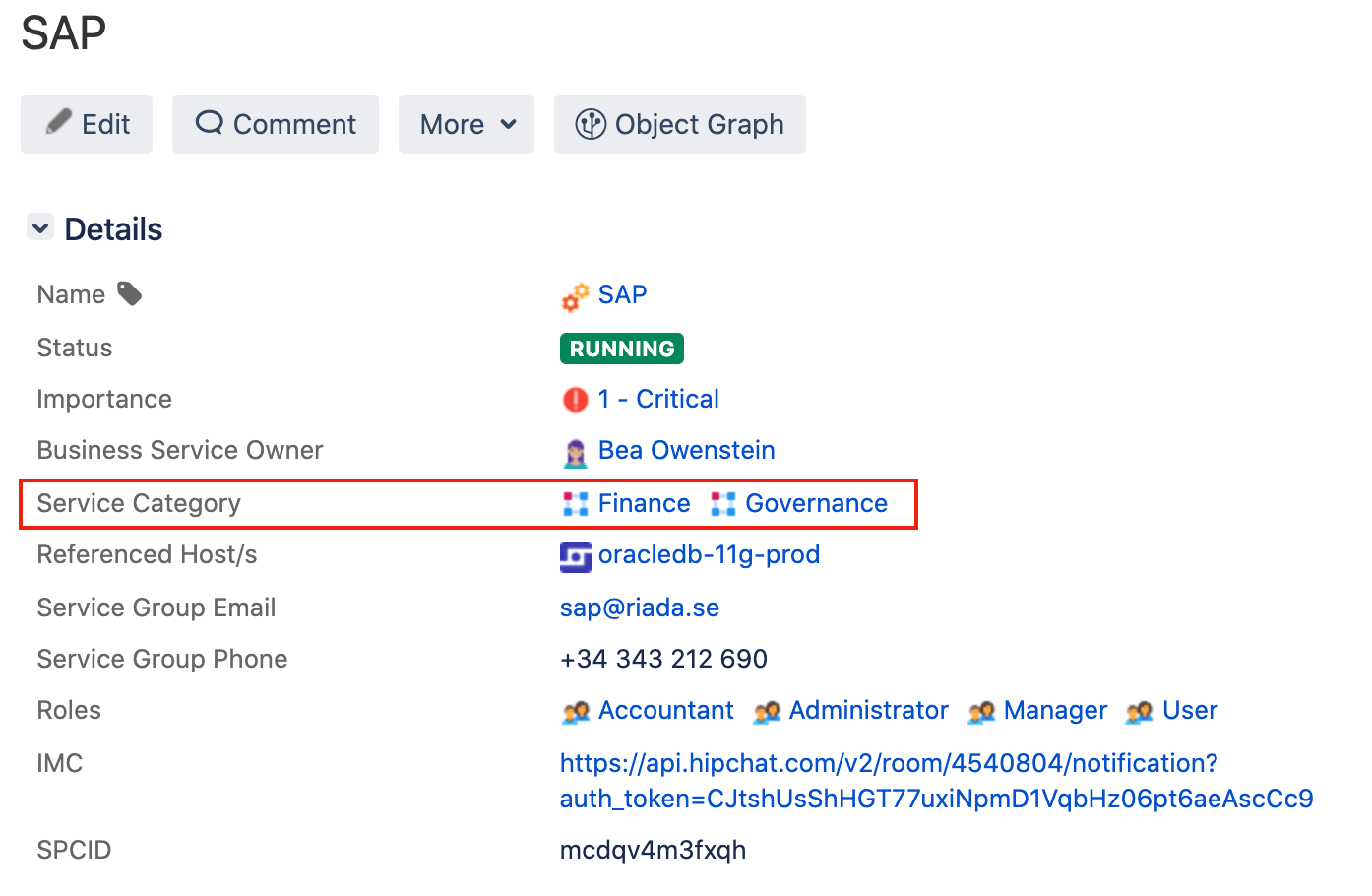
The benefit of this is that you can add details (attributes) specific to the business service category. Maybe there’s someone responsible for all finance business services. You don’t want to add that person directly to every finance “Business Service” object as it will become harder to maintain. Instead, you just add it once to the “Finance” object in the “Service Category” object type and now you only need to update it in one place and don't have to repeat data.
You can also have rules that take the operation status of each individual finance business service and roll them up into an overall status for the finance category. Now you can quickly see if there are any service problems with each category of service by viewing the category objects.
You don’t need to add these types of objects to Assets but it’s important to know that you’re not limited by traditional assets/configuration items. It all depends on what you want to do which is why understanding your goals and the information you need to achieve them is so key.
Look ahead and grow gradually
Keep in mind any extensions you may want to do in future. This will both shape what data you choose to include, but also how you structure your data.
While it’s good to keep it in mind, we do recommend building Assets up in a gradual way. Trying to do one huge big release with 100% accurate data for 1000s of objects is very tough. Starting small and adding new attributes, objects, and object schemas as you go is going to be significantly simpler.
Our recommendation is to find a problem, build up Assets to fix it, then move onto the next problem, growing Assets as you go.
Set realistic expectations for accuracy
100% accuracy at all times should be the goal but in reality, that may not be possible and that’s okay. As long as the data is sufficiently accurate enough to offer more business value than not having it in the first place, then you’re in a net positive. Many CMDB projects can be delayed or even fail as they’re waiting to be ‘perfect’ before go-live.
Step 7 - Set up automations
This section takes a look at the two options you have for automating repetitive tasks in Assets.
Assets automations
Assets automations are specific to each object schema. Common uses include:
- Sending notifications based on certain triggers or changes with the Assets objects in the schema - e.g. sending an email when a license or warranty is due to expire, or creating a Jira issue if a service goes down.
- Keeping Assets data tidy and standardized for easy reporting and querying.
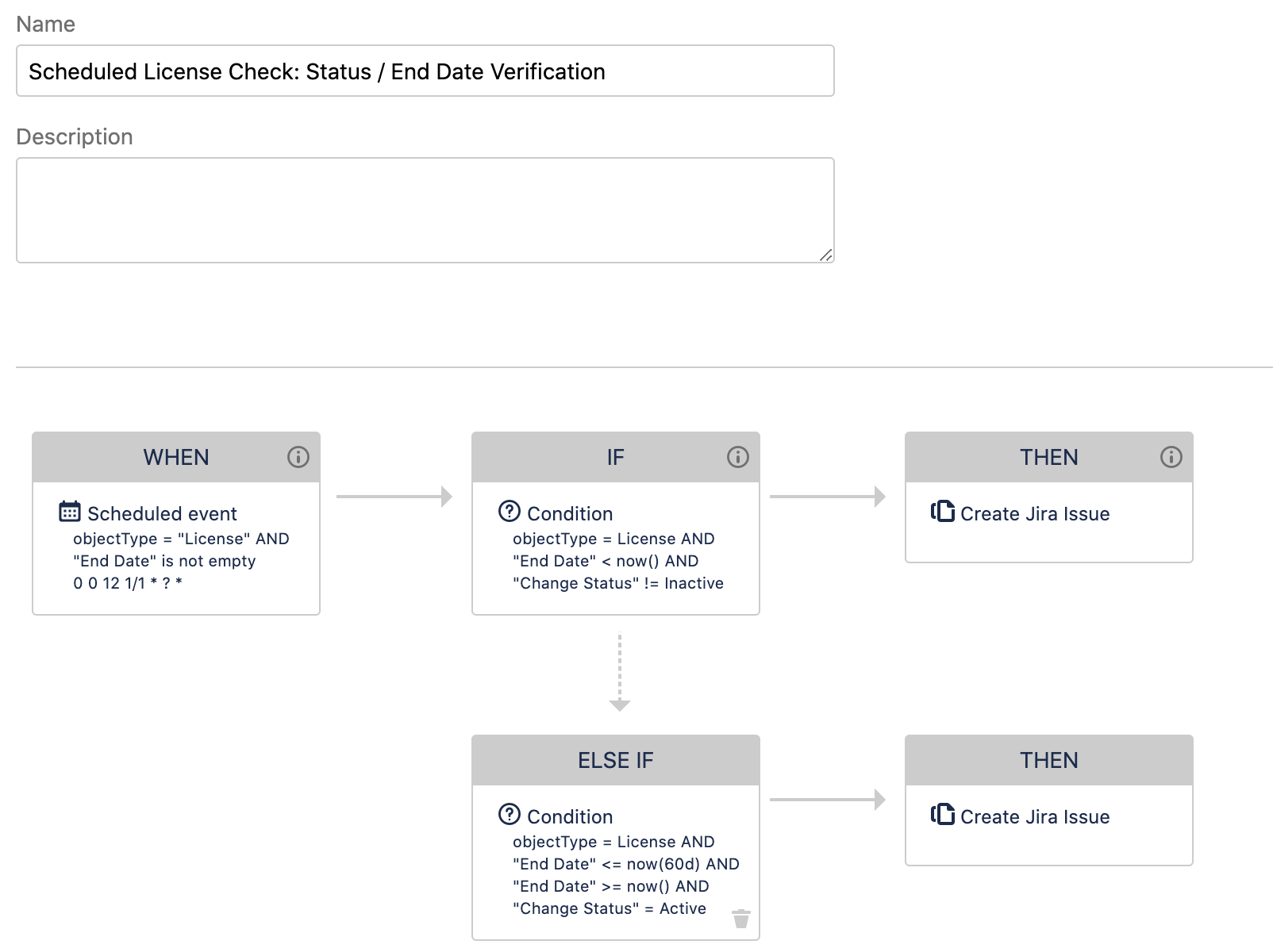
Automation rules can update object information, create issues, send emails, make HTTP requests, execute Groovy scripts, and more.
You can see how to create automation rules here:
Post functions
Assets also introduces new post functions. Similarly to automation rules, post functions allow you to automate the execution of actions.
The difference is that the actions take place when the status of an issue changes through a Jira workflow (issue transition). These actions include updating an asset, sending a notification, and running a script.
For instance, when an issue is created requesting the onboarding of an employee, tasks can be created to assign the necessary assets to the new user including laptop, cell phone, and cell phone subscription with linked Assets objects for each.
Tips & Tricks
If you are using issue text fields to enter or update data in Assets, or if you enter objects into Assets manually on occasion, there may be times when the data becomes a bit messy. In these cases, use automations.
Server names are a good example of this. Usually these will be standardized and might be easy to mistype. You can create automation rules that trigger when an object is created or updated of the type server to ensure the name meets the naming convention and flag it if it spots an error.
Step 9 - Set up reporting
Reporting is very specific to you and your company and the problems you are trying to solve with Assets. Assets comes with a number of pre-configured reports to help you understand your assets and configuration data. You can report on your Assets objects, their related issues and projects, as well as the time spent on them.
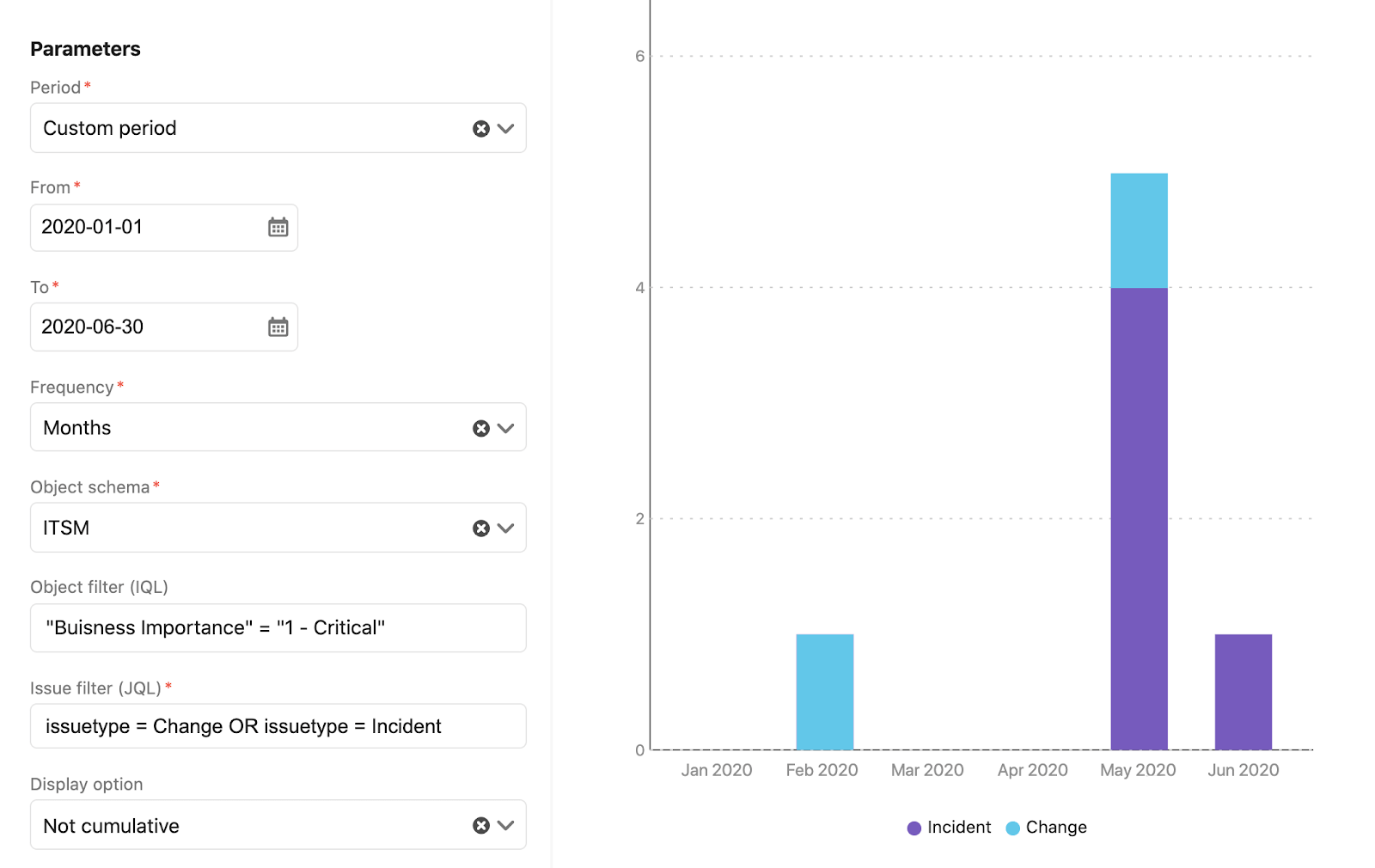
For example, you might want to understand how many changes and incidents have occurred with your critical business services, or if there is a pattern with the time spent on service requests and the types of assets they’re related to. You could use reports to see which critical business services have the highest number of linked incidents so you can understand where to prioritize any improvements.